







Share this article

Building a smarter retrieval system: Lessons from Vanta AI
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
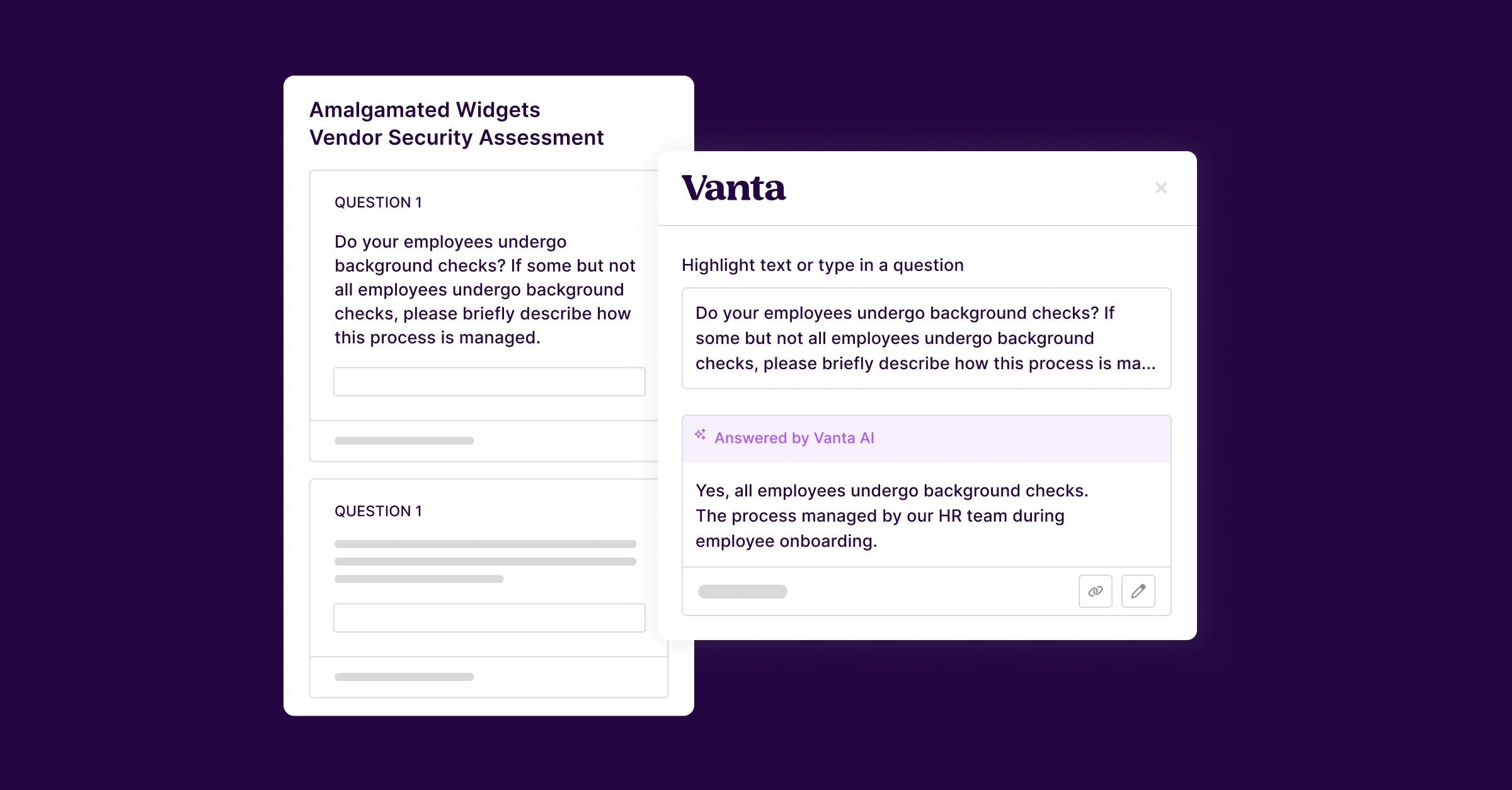
At Vanta, we power a suite of AI products that enable thousands of customers worldwide to make critical business decisions. These products rely on the ability to quickly search through millions of customer documents to surface relevant information and drive accurate outcomes.
Building a retrieval system capable of handling this scale and complexity was no small feat. Along the way, we learned valuable lessons that we’re excited to share. Here’s how we designed and optimized Vanta’s AI retrieval system.
#1 Start with a robust evaluation system
The foundation of any successful project is defining what success looks like. As the saying goes, “You can’t improve what you don’t measure.” For us, this meant creating a comprehensive evaluation dataset that included:
- A wide variety of document types
- Sample queries tailored to those documents
- Relevancy annotations provided by internal subject matter experts (SMEs)
To ensure our system could handle the nuances of compliance-related queries, we included specific terms and concepts such as “encryption at rest” vs. “encryption in transit,” “MFA (multi-factor authentication)” vs. “2FA (two-factor authentication),” and acronyms like “BYOD (bring your own device) policies.”
We approached this process with a test-driven development (TDD) mindset, where we defined success metrics and evaluation criteria upfront. This allowed us to iteratively test and refine our retrieval system against clear benchmarks. We measured retrieval quality using both isolated metrics—precision@k, recall@k, Mean Reciprocal Rank (MRR), and F1—and end-to-end performance.
This dual approach allowed us to evaluate not only the accuracy of retrieved results but also their interpretability and overall impact on the system. By incorporating varying levels of difficulty in our dataset, we identified areas where the system excelled and where it needed improvement, significantly reducing the effort required to address gaps.
#2 Optimize your chunking strategies
One of the most critical decisions in building a retrieval system is how to segment documents into smaller, manageable chunks of text. Naive approaches, such as fixed-size or page-based chunking, often break apart related concepts, leading to reduced retrieval quality—especially for compliance-related queries. For example, long tables spanning multiple pages lose context if not properly chunked.
We experimented with several strategies, including:
Through our evaluation framework, we discovered that preserving hierarchical elements—such as headers, subheaders, and structured data like tables—significantly improved retrieval performance. For compliance documents, section headers provide crucial metadata that helps disambiguate similar concepts appearing in different contexts.
By adopting context-aware chunking, we maintained continuity and minimized the risk of splitting key information across chunks. This change alone resulted in a 16% improvement in recall and a 15% improvement in MRR.
#3 Don’t overlook lexical search
While embedding-based semantic search is powerful, we found that combining it with traditional lexical search (BM25) significantly enhanced retrieval performance, particularly for compliance-specific terminology and acronyms.
Lexical search excels at exact matches and specialized terminology that may not be well-represented in general-purpose embedding models. For example, compliance framework references like “SOC2 CC6.1” or “ISO 27001 A.9.4” are better handled by lexical search.
We implemented a hybrid search approach that combines semantic and lexical search, using reciprocal rank fusion to merge results. This allowed us to capture both specific terms and broader conceptual queries effectively. After introducing hybrid search, we saw a nine percent improvement in recall, while MRR remained stable.
#4 Enhance results with reranking
To further improve retrieval quality, we introduced a reranking step. Using Cohere’s v3.5 multilingual rerank model, which leverages cross-attention to better capture the relationship between queries and documents, we addressed cases where initial retrieval returned semantically similar but contextually irrelevant results.
For example, reranking helped distinguish between employee security training requirements across different compliance frameworks. While reranking adds some latency, running it on a smaller set of initial results (top-k=50) struck a balance between quality and performance. This step delivered a six percent improvement in recall and a twenty-one percent improvement in MRR.
Conclusion
Building an effective retrieval system requires addressing domain-specific challenges through careful evaluation and iteration. By optimizing our chunking strategy, combining lexical and semantic search, and introducing reranking, we improved our system’s recall by 40% and MRR by 22%. These enhancements are now live in production, powering thousands of customer decisions daily across our AI products.
As we look to the future, we’re excited to explore new ways to push the boundaries of retrieval technology. From advancements in multimodal and personalized search to leveraging the latest innovations in AI, we’re committed to evolving our system to meet the ever-changing needs of our customers.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.

.png)









.svg)
.svg)


