







Share this article

How we standardized error handling at Vanta
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
Part 1: From wild goose chases to efficient debugging
I love working in monolithic repositories. It fosters collaboration, code reuse, and knowledge sharing—some of my favorite aspects of engineering culture here.
However, without guardrails, complexity can grow unchecked, making it harder to reason about the system as a whole. In early 2024, it was clear that our error handling strategies had fallen victim to this, and it was impacting the quality of our product. One example was how errors surfaced to the frontend in the form of one overly generic toast across the entire web application.
Error handling affects both customers and engineers
When I joined Vanta in January 2023, we had a single toast in the web app to handle errors.

Whenever the server returned a status code in the 500s, users would see this message. The great thing about this toast was that it worked in almost every situation! The terrible thing about this toast was that it worked in almost every situation. It gave no information to customers about what went wrong, how bad it was, or even what they could do to fix it other than contact support.
Contacting support should not be the first line of defense when it comes to customer issues, it should be one of the last.
On the other side of the table, our support and engineering teams were having trouble debugging when customers followed the toast's advice. Customers would write in with a screenshot and a brief description of their issue. Sometimes it was easy to find the corresponding line of code, but usually it was almost impossible and engineers would spend hours on wild goose chases.
Speaking a common language
Our first step to fixing this was to understand the depth of the problem. Taking inspiration from a number of sources including Google, Web standards, and the array of built-in GraphQL error codes, we put errors into two main categories:
- User input errors, when the user did something wrong and they can fix it themselves. For example, misspelling something in a form or searching for something that doesn’t exist.
- Internal server errors, when something went wrong on our end and it’s not the user’s fault. These can range widely from bugs in the code to problems with our servers, but we always want to know when these errors happen.
We went through a mapping exercise to categorize our existing errors. From there, we could plan mitigation strategies: for the user input errors, clearer UX goes a long way to resolve our customers' pain point, while internal server errors required a fast developer response to triage the issue.

Introducing canonical errors
During the mapping exercise, we got a sense for the common themes that were consistent throughout the codebase. We settled on a set of canonical error codes that everyone could use: fundamental concepts such as InvalidInputError, NotAuthorizedError, ResourceNotFoundError, etc. We focused on keeping the list small so that teams would be forced to make tough decisions and decide if the extra work for custom errors was really necessary.
These error types were designed for a “plug-and-play” experience, requiring minimal setup and incentivizing teams to adopt the new system with many rewards:
- Automated monitoring: Configurable alerts notify us of internal server error spikes so we can detect and resolve issues before they reach customers.
- Seamless GraphQL integration: Errors are logged “automagically” on both the client and server via the Apollo Error Link and GraphQL middleware.
- Improved user experience: React error boundaries ensure the rest of the page remains functional when a component encounters an error.
- Simplified debugging: Canonical error codes make it easy to search logs and trace issues back to their source.
- Long-term maintainability: A standardized system ensures that error handling continues to evolve and improve under the stewardship of our platform teams.

Our biggest learning: use the language!
It sounds obvious in hindsight, but in many parts of our original error handling process, we were trying to be too clever. Most companies, big or small, don’t need fancy error handling systems. As Vanta has grown, we’re constantly validating the fact that simple systems stand the test of time and pay off because they are easy to understand and use.
By leaning into the utilities provided by Typescript and the Apollo client, we’re able to clearly delineate expected and unexpected code paths idiomatically and make the right path also the one of least resistance. This work also prepared us for releasing our public API in October 2024, since we had defined our canonical errors with HTTP status codes in mind.
Where are we now?
That “uh oh!” toast I mentioned in the beginning? We cut it down by 8x.
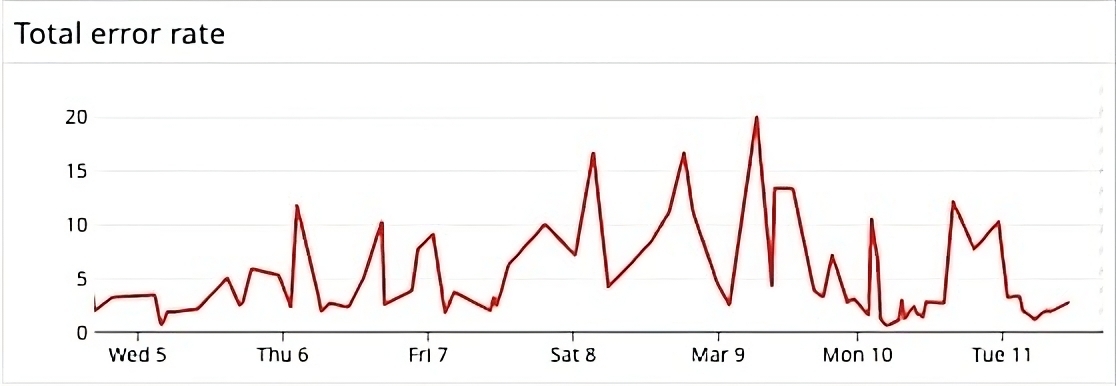

These changes kicked off large efforts from engineering teams to drive down alerts. This journey reinforced an important lesson: the best engineering solutions aren’t always the most complex—they’re the ones that make everyday work simpler and more effective.
And the best part? Engineers now spend less time chasing down error logs and more time building delightful features for our customers.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.











.svg)
.svg)


