







Share this article

Vanta’s agent development principles
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
This blog is part of our Trustcraft series, in which we dig into Vanta’s approach to building with AI. Read the first blog in this series to learn more about how we define Trustcraft.
As we’ve moved from LLM features to agentic systems, we’ve had to update how we think about building with AI. A prompt is no longer the product. The product and outcomes are the loops around the model: the tools it can use, the context it gets, the verifiers it listens to, the traces we inspect, and the ways it recovers when it’s wrong.
I’m Noam Rubin, a Staff Software Engineer at Vanta. These are the principles we’ve been using while building agentic systems at Vanta.
1. Always bet on model intelligence
Don’t assume you know better than the model—whatever you’re asking it to do, the model knows how to do it, or will know how to do it in a generation or two. With all the frontier labs building foundation models, we barely go one month without a major benchmark-defining release. In the time between model releases, the harnesses continue to squeeze more intelligence per token and prompt.
Betting that models will plateau in their capabilities, intelligence, cost efficiency, or latency has been a losing bet for years, too. Competition in hardware, frontier labs, and open-source labs continues and is producing wins across the entire Pareto Frontier for LLMs.
Continuous improvement is the only way AI features stay competitive. If you’re not bumping to the latest models or looking at your data or shipping, your features will fall behind as models get smarter. Of all the work you’ll do on your AI feature, the largest quality gains will likely come from using a newer model and giving it more degrees of freedom.
Whatever assumptions you have about what an LLM can do, you need to reassess those assumptions with every new model release, alongside understanding what inputs/context the model might be missing. Most likely, the task that seems impossible today will be possible tomorrow.
2. Composition enables emergent behaviors
As models get smarter, focus less on telling them what to do and more on giving them the ability to complete a task and choose their own path (via tools/skills/knowledge).
Legislating how a task gets done is limiting and doesn’t allow you to take advantage of a smarter model. Giving the model capabilities allows it to compose them to complete the task you’re working on and a dozen other tasks you haven’t thought of (but your users will ask for).
Think of instructing the model like you’d instruct a reasonably intelligent coworker: it must know the goal/outcome and be given the tools/skills to achieve the goal.
Composition also carries its risks. Simon Willison’s Lethal Trifecta framework is one we talk about internally a lot: We want to build highly capable agents via composition without sacrificing security or customer trust.
3. Make loops: Strong verifiers bootstrap strong generators
Models are good at coding because coding is a verifiable task. There are other tasks you’re automating for your users that are probably verifiable (i.e., there is a “right” outcome and a “wrong” outcome).
Building a strong verifier is valuable because:
- You can tell your users if they’re doing it wrong
- You can use it to make sure your generators are doing the right thing at inference time
Modern coding harnesses use loops a lot. Tools like /goal in Claude and Codex put coding agents in loops, checking themselves against unit tests, CI, or visual verification.
When we build our agentic products, like agentic evidence collection, we proactively seek these loops and build what we call “strong verifiers” to make these loops successful. Strong verifiers are our unit tests: They are agentic systems, battle-tested across an extensive number of completions and evals, that reliably predict success.
A real-world example
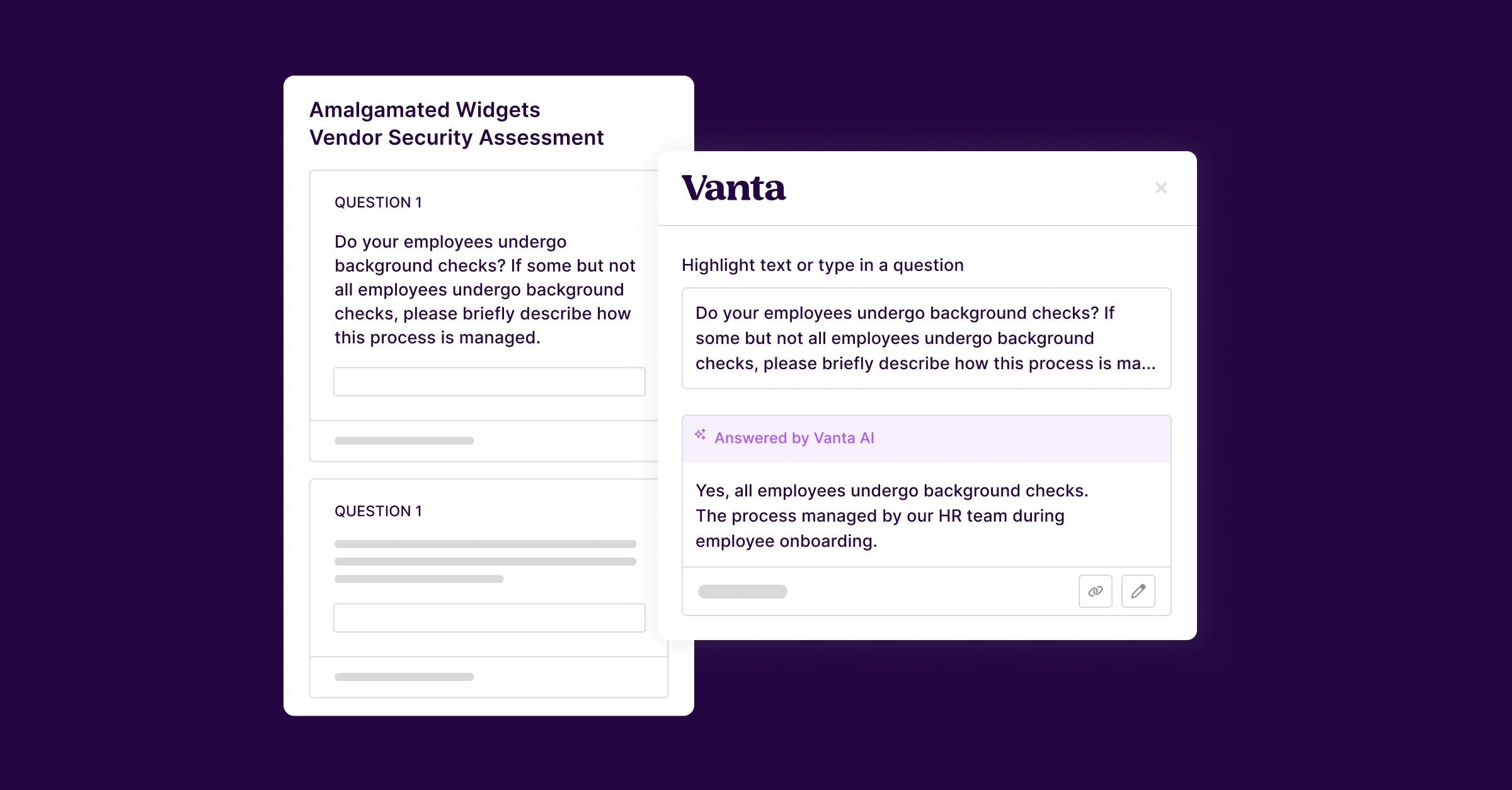
An example of this verifier is our evidence evaluation agent. This tool checks unstructured compliance as it’s uploaded into Vanta, giving humans and agents real-time feedback on how well they are proving trust.
We pair our evidence evaluation agent with our browser-using evidence collection agent to create a loop:
- The browser collection agent looks for evidence of a compliance practice
- When it finds this evidence, it evaluates it using our evidence evaluation agent
- Our evidence evaluation agent then provides feedback (the same feedback we provide to humans)
- The browser collection agent uses this feedback to tune its search
Adding the evidence evaluation agent to our browser agent doubled our successful task completion rate. Loops are key!
Strong verifiers are not always easy or feasible to build—evidence evaluation has been iterated on for more than a year. But when they exist, they enable whole new use cases.
4. It’s all about the context
This is a corollary to principle 1: If models are getting so much smarter, why do they continue to fail on my task? The answer is usually context—we haven’t told the agent the right things or given it the right data.
We have three tricks for debugging agent failures that often identify context issues:
- Asking our agents why they did something dumb
- Asking our agents what data they’d want to have to give a better answer
- Asking our agents to ask users for context (this one is my favorite)
These are really simple debugging and agent behavior tricks that create much better agentic products. The last one, paired with features like Memory, makes agentic systems that continuously improve from usage.
5. There is no maintenance mode
AI features are living, breathing systems that must constantly improve to take advantage of the newest models and updated user expectations. You’d be shocked how fast user expectations are evolving for AI features. So if you’re not looking at the data for your feature and making improvements, you should kill your feature.
Learn more about how Vanta builds with AI
Check out the other blogs in our Trustcraft series to see how we approach measuring AI quality or to learn why AI hasn’t killed the design doc.
Or, if this is how you think about building, we'd like to talk. See open roles at Vanta.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.



.png)






.svg)
.svg)


