







Share this article

Trustcraft: How we build AI products at Vanta
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
More than 16,000 companies use Vanta to continuously prove their security posture every day, not just once a year to pass an audit or achieve a certification. Increasingly, our AI is part of how that work gets done.
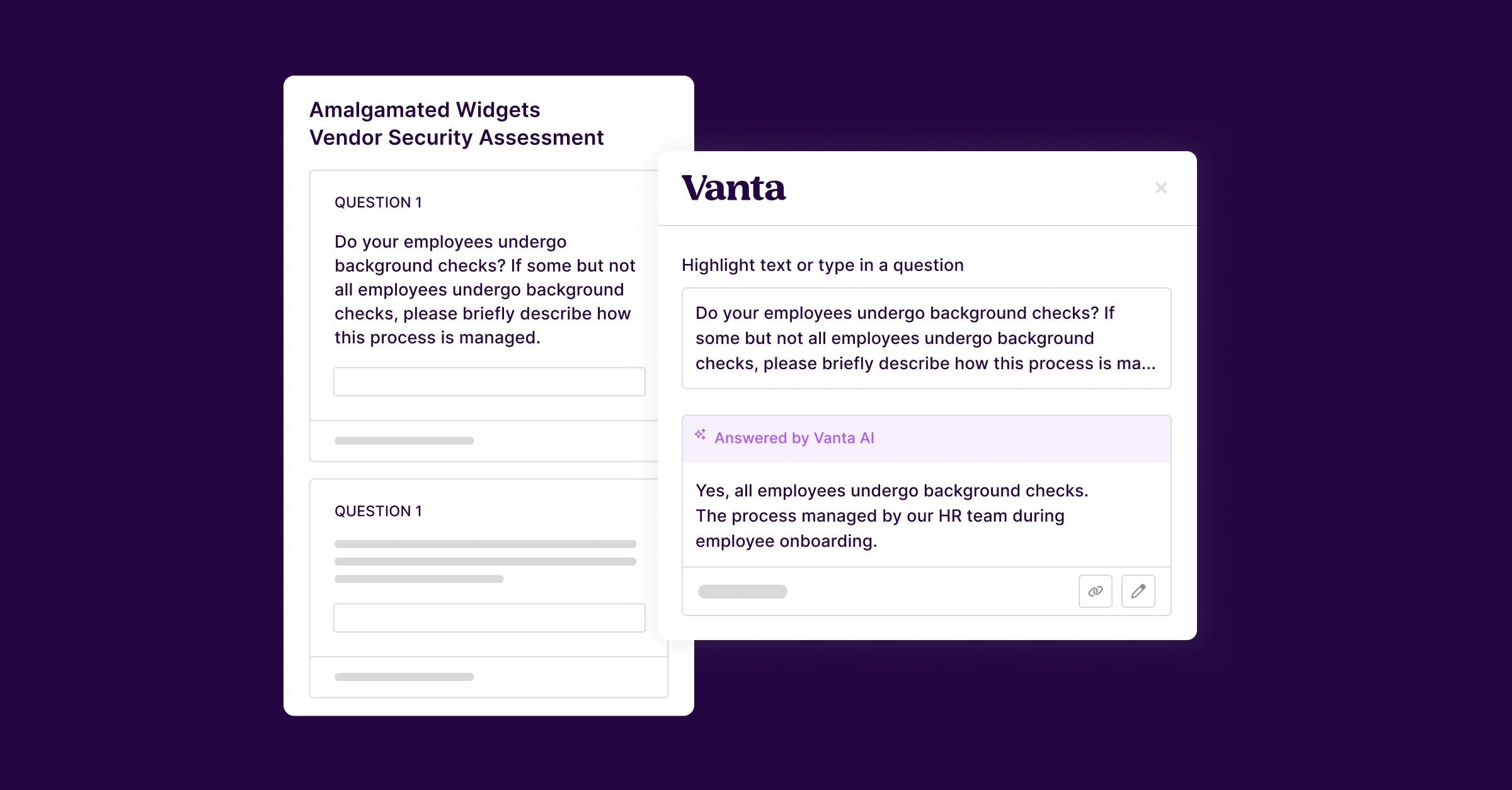
When an agent recommends a control, verifies a piece of evidence, or pulls a commitment out of a contract, the bar can't be "good enough to demo." It has to be good enough that a compliance team can stake their program on it, for their auditors and, more importantly, for their own customers in turn. We hold ourselves to that.
Most of the work that gets us there happens in the system around the model: the data we put in front of it, the GRC experts who calibrate the evaluators, the eval discipline that catches problems before customers do, the dogfooding that catches the things demos hide.
We call this approach Trustcraft. This post is about how we apply it.
Solve real customer outcomes, don’t sprinkle AI on the surface
A lot of AI features in B2B software are chatboxes with a personality. They make a product feel modern without doing any of the work the customer was trying to do. We call this AI sprinkle, and we don't ship it at Vanta.
AI can and should fix a root cause, not just treat a symptom. At Vanta, an AI feature has to map to a job a customer was already trying to do, like proving their security posture, fulfilling a contract commitment, fixing a failing control, or answering a security questionnaire. If a feature pitch starts with "the AI helps you" instead of "the customer can finally"— then it isn't ready.
The hardest part of building AI in compliance isn't getting the model to work; it's having the discipline to keep saying no to features that look great in a demo and fall apart in a real workflow.
Meet customers where they already work
The customer using your product already has tools they like: an IDE with a coding agent, a CI pipeline, a ticketing system, etc. When we evaluate a new AI feature, the question isn't whether it's smart in isolation. It's whether it slots into a surface the customer is already using. We'd usually rather make the customer's existing agent smarter at compliance than ask them to context-switch into ours.
This is an intentional design choice. The customer's coding agent has more context about their repo than we ever will. Our job is to bring Vanta's compliance intelligence wherever they're already working—through the MCP server, the public API, the agent surfaces—and let our intelligence make their existing tools sharper.
The Trust Graph is what we plug into
LLMs don't know about a customer's controls, evidence, vendor relationships, contract commitments, or test results. We do. Years of building Vanta have produced what we call the Trust Graph: a continuously refreshed model of a customer's compliance posture, integrated across hundreds of systems and validated by thousands of automated tests. Every AI feature we ship reads from that graph. Without it, an LLM in this domain is mostly guessing.
We expose the graph too. The Vanta MCP server, our public API, and our agentic surfaces are all entry points into the same data. A customer who wants to use their own coding agent, their own analytics tooling, or their own internal workflows on top of Vanta should be able to. The compliance intelligence is the product. The chat surface is only one way to consume it.
Quality comes from our GRC experts, not from training on customer data
Vanta does not train models on customer data. It’s a commitment we made early on to our customers.
Our quality comes from three places: a deep bench of GRC subject matter experts (who have been former heads of security, auditors, etc.) who calibrate the evaluators; offline datasets we build and version ourselves; and a multi-dimensional eval discipline (observability, curated datasets, calibrated evaluators, systematic experimentation, feedback loops) that we'll go deeper on in a follow-up post. Most companies reach a comparable quality bar by reaching into customer data. We get there through our SMEs instead. It's slower, and it's also why we sleep well at night.
What you measure is what you get
Engineering instinct turns out to be unreliable in this domain. Models that should be better often aren't. Approaches that should be obsolete sometimes outperform their replacements. Prompt changes that read well sometimes regress on the cases that matter. We've been wrong about this enough times that "let's measure" is now the default answer to most AI design questions: what model to use, how to chunk context, where to set a confidence threshold, whether a wording change actually helps.
This isn't only how we maintain quality. As counterintuitive it may seem, we also complement the data with taste and human judgment.
Trace every AI call
Every customer-facing AI call at Vanta is traced: every prompt, every response, every tool invocation, every latency. When a customer asks why an agent recommended a particular control, flagged a specific commitment, or generated a specific remediation, we can pull up the exact session and tell them what the model saw, what it did, and (when relevant) what went wrong. When a prompt starts regressing in production, alerts fire before a customer feels it in their workflow.
A lot of AI products run on the hope that nothing ever goes badly enough to need an audit trail. That isn't a posture a trust company can take. Traceability is what separates an AI feature from an accountable AI feature, and the second is the only kind we ship.
We use it before our customers do
Every customer-facing AI feature at Vanta is dogfooded inside Vanta first. We run on Vanta: our own SOC 2, our own ISO program, our own vendor reviews, our own questionnaire automation. If a feature isn't good enough for our compliance team to rely on, it isn't going to a customer. We're the first eval. We would rather hear about it from our own GRC team than from a customer in the middle of an audit.
Principles only matter if they show up in the work. A few recent examples.
Story one: Agentic test remediation, via the customer's own coding agent
Arnim Jain and Michael Barlock mapped Vanta's full test catalog (1400+ automated compliance tests) and asked which of them a customer's coding agent could fix if we gave it the right context. The answer surfaced the percentage of tests where the failing resource lives in Terraform or CloudFormation and where Claude Code, Cursor, Codex, and GitHub Copilot are already doing the heavy lifting. The bottleneck was that the agent didn't know what compliance required.
So the team didn't build a competing code-generation agent inside Vanta. They built a packaged plugin that bundles Vanta's remediation intelligence - system prompt, test context, failing resources, safety guardrails - with a connection to the Vanta MCP server. The customer installs it in their existing coding agent, says "fix my failing Vanta tests," and gets customer-specific Terraform changes generated against their actual repo. The pilot is targeting 90%+ remediation success and under five minutes from click to generated diff. The customer's coding agent is the consumer; we didn't build a new agent, we made every existing one better at compliance.
Story two: Customer Commitments AI
The Customer Commitments team faced a problem most companies have and almost none have solved: Every contract creates dozens of obligations (SLAs, audit rights, subprocessor notification windows, data-handling promises). And when something happens—an incident, a subprocessor change, an audit—nobody can find them. Mikaela Gilbert, Gwyneth Ross, James Park, Alex Vu, Krish Penumarty, Ajay Gandhi, and Kevin Chen built AI extraction that turns contracts into a structured, searchable inventory of commitments tied to the customer who signed them.
Standard Commitments recently shipped with auto-tracking, export by type, and APIs. The thing that made it shippable was the eval harness underneath, making it possible to monitor for issues with commitment precision, recall, and duplicate detection. When subprocessor change notices started showing duplicate-detection drift, the eval caught it before customers did, and the team shipped a fix that improved both recall and precision.
Story three: The eval harness that outlasts the model
Dennis Chen's work on policy control recommendations is the canonical example of what we mean. The feature was missing some controls and over-suggesting others. In a two-week sprint, Dennis set up an updated eval dataset with our deep bench of GRC subject matter experts, upgraded the underlying model, split the prompt into two stages so each could be tuned independently, and measured the result: 2× faster, +12% precision, +17% recall, and the elimination of a class of context-window errors. The model Dennis used will be obsolete within a year, but the eval harness he built will still be running, still be right, and still be what lets us ship the next model confidently.
Trustcraft is the product
It would be easier to ship AI features without any of this, and most companies do. They wire up an LLM, demo it, and move on. We can't, and honestly, we wouldn't even if we could. Our customers use our AI to make decisions that an auditor or regulator might scrutinize.
The model that generated the answer matters less than the system around it: the data, the SMEs, the traces, the evals, the rollback safety nets, the dogfooding. That system is what we mean by Trustcraft, and it's what we sell.
We'll keep writing about it. A deeper companion post on our eval maturity model is up next, and we'll share more concrete stories from the teams shipping these features. If this is the way you want to build, we're hiring.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.










.svg)
.svg)


