







Share this article

The Vanta AI Quality Eval Maturity Model
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
This blog is part of our Trustcraft series, in which we dig into Vanta’s approach to building with AI. Read the first blog in this series to learn more about how we define Trustcraft.
You've seen what ChatGPT and Claude can do. You've heard about MCPs, CLIs, and APIs that let you wire a foundation model into just about anything. So when you look at Vanta's AI features, a fair question might come up: Why not just connect a general-purpose LLM to your own company’s data sources and call it a day?
It's a reasonable instinct. But after building AI systems that serve thousands of customers across compliance, trust, and security workflows, we've learned something that isn't obvious from the outside: The gap between a raw LLM integration and a production-quality AI product is enormous, and it widens as the stakes go up.
This post is about what lives in that gap.
The ‘just connect an LLM’ illusion
Foundation models are extraordinarily capable. But capability and reliability are not the same thing. In compliance and security, “good” means correctly interpreting control requirements, evaluating evidence accurately, handling regulatory edge cases, and never hallucinating details that could put your audit at risk. A raw LLM integration gives you a coin flip on each of these. Vanta's AI is engineered to get them right, repeatedly, at scale.
The difference isn't the model, but everything around the model—the prompts, the context retrieval, the memory, the domain-specific scaffolding, and the system design that turns a general-purpose model into a compliance-ready tool. When you use Vanta's AI, you benefit from deep, focused work put into every one of those layers.
When you use Vanta, you don't need to be a prompt engineer, you don't need to design your own retrieval system, and you don't need to stitch together context about your controls, evidence, and frameworks. It just works. When you connect ChatGPT or Claude to an API yourself, you're responsible for building all of that, or accepting worse answers.
Meet the framework that holds every Vanta AI feature to the same rigorous quality bar
To ensure we’re producing production-quality AI products, we don’t just ship anything. However, as our AI portfolio grew, we noticed a problem: Our AI teams didn't have a shared understanding of what "good enough" looked like for quality and evaluation. Teams were building great features but evaluating them inconsistently—different standards, different tools, different levels of rigor.
So we built a rigorous, multi-dimensional quality system we call our AI Quality Eval Maturity Model, which now governs how every AI-powered capability at Vanta is developed, measured, and improved over time.
The model evaluates our AI systems across five critical dimensions, each representing the ideal state we hold our teams to:
- Observability: Full trace coverage across every AI interaction—inputs, outputs, reasoning steps, and metadata—with real-time monitoring and automated alerting when behavior drifts.
- Curated evaluation datasets: Versioned, actively maintained datasets curated by our GRC subject matter experts. Not ad-hoc test sets, but evolving collections that reflect real-world complexity.
- Calibrated evaluators: Formal evaluation pipelines, including validated LLM-as-a-judge systems, calibrated against the expertise of our subject matter experts and Vanta's deep trust and compliance domain knowledge. This ensures our quality assessments are consistent and aligned with what actually matters in production, not just what a model thinks is correct.
- Systematic experimentation: A structured, repeatable experiment-and-analysis cycle for every AI change, with clear criteria for measuring impact and determining next steps.
- Integrated feedback loops: Explicit and implicit user feedback are automatically captured, tagged, and linked back to evaluation datasets, creating a continuous cycle where real customer experiences drive improvement.
How our work has changed with the Eval Maturity Model
We score every AI team across each of the five dimensions using a simple rating system: Red (Foundational/Reactive), Yellow (Systematic/Developing), and Green (Advanced/Proactive).
When we first ran this assessment, the picture was humbling. Most teams were deep in red and yellow, relying on ad-hoc datasets, inconsistent evaluation processes, and manual feedback loops. We had the same gaps that most organizations building with AI have today.
But that's exactly why the model exists. We standardized our evaluation tooling so every AI team could leverage the same infrastructure, educated teams on evaluation best practices, and had our AI platform team partner closely with each product team to help them level up.
The result: Teams that were once deep in red and yellow have reached green across many dimensions.
All green is not the goal
It’s worth noting that reaching "all green" across the maturity model isn't the end goal. The real end goal is to produce high-quality AI features that customers can trust. In the same way that perfect test coverage doesn't guarantee a great software product, a perfect maturity score doesn't guarantee great AI. The maturity model is the practice that gets us there. It’s a discipline of measurement, evaluation, and continuous improvement that requires dedicated investment, not just plugging into an API.
Quality and speed
Here's what might be counterintuitive: Investing in AI quality doesn't slow us down. It makes us faster. After establishing deep observability, curated datasets, and calibrated evaluators, we can ship a change and know within hours, not weeks, whether it improved things or broke them. We catch regressions before customers do.
We don't train on customer data
This is worth restating: Vanta does not train AI models on customer data.
Every quality improvement we've made—every evaluator we've calibrated, every dataset we've curated, every feedback loop we've closed—has been achieved without using customer data for model training. Our quality comes from engineering discipline, deep domain expertise built from working with thousands of customers, and a relentless evaluation practice.
This matters because customers get the benefits of an AI system that deeply understands compliance and trust workflows, without the privacy tradeoff that other approaches might require.
What this looks like in practice
Our AI Quality Maturity Model enables our teams to iterate quickly and deliver measurable improvements across Vanta's AI features. Here are a few examples:
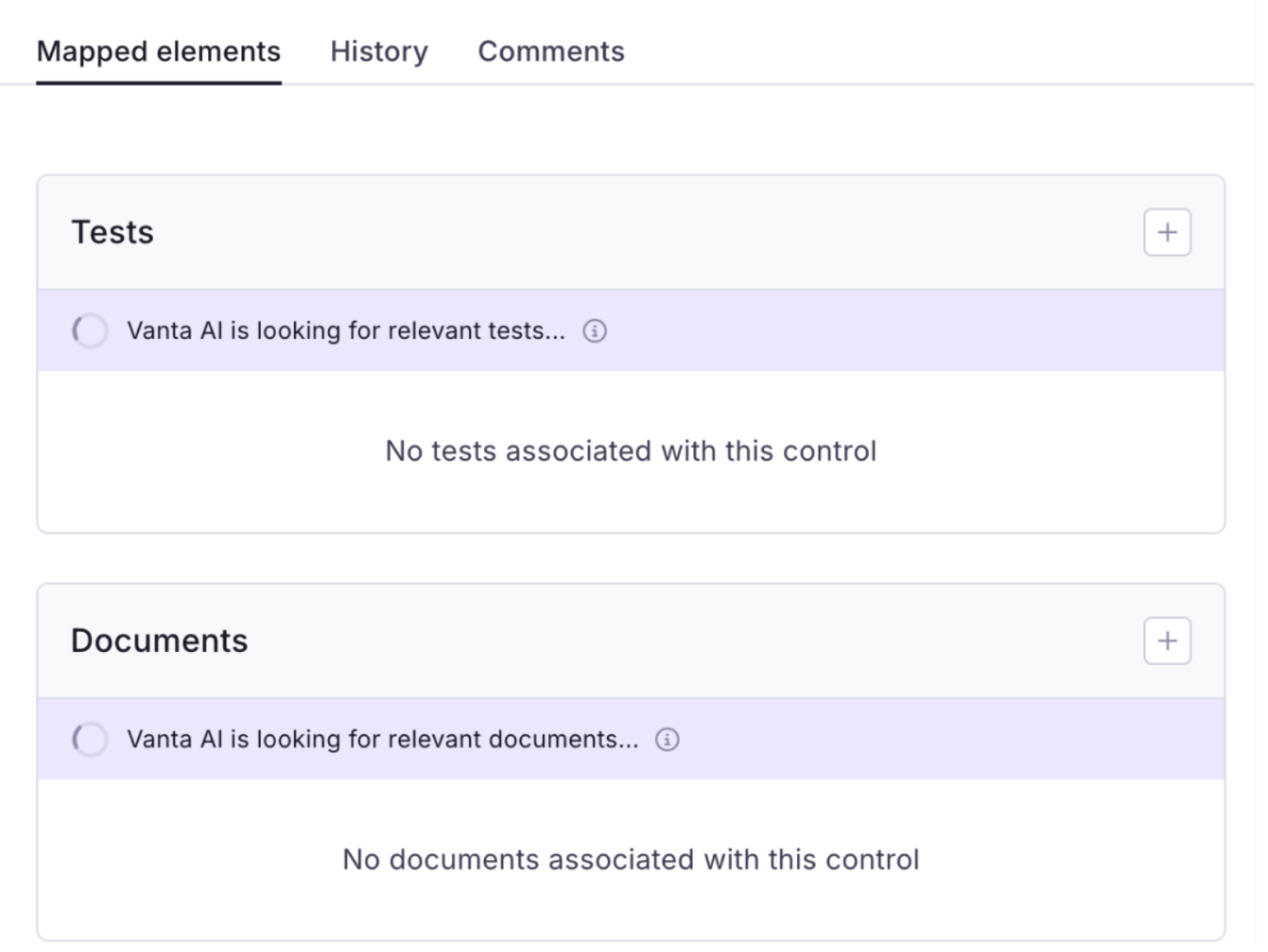
Control-to-evidence mapping
Our AI-powered control-to-evidence mapping feature wasn't meeting the quality bar our customers deserved. Rather than guessing at fixes, the team followed the maturity model playbook: They built an offline, comprehensive evaluation dataset of thousands of evidence suggestions across an extensive range of control descriptions, then ran a baseline experiment that revealed precision was below 35% (with high recall—the model was casting too wide a net).
With a proper evaluation setup in place, the team was able to iterate rapidly and with confidence. The next round of improvements took precision to 78%, more than doubling accuracy while maintaining coverage.
Vanta AI will suggest the right evidence mapping to the newly added control.
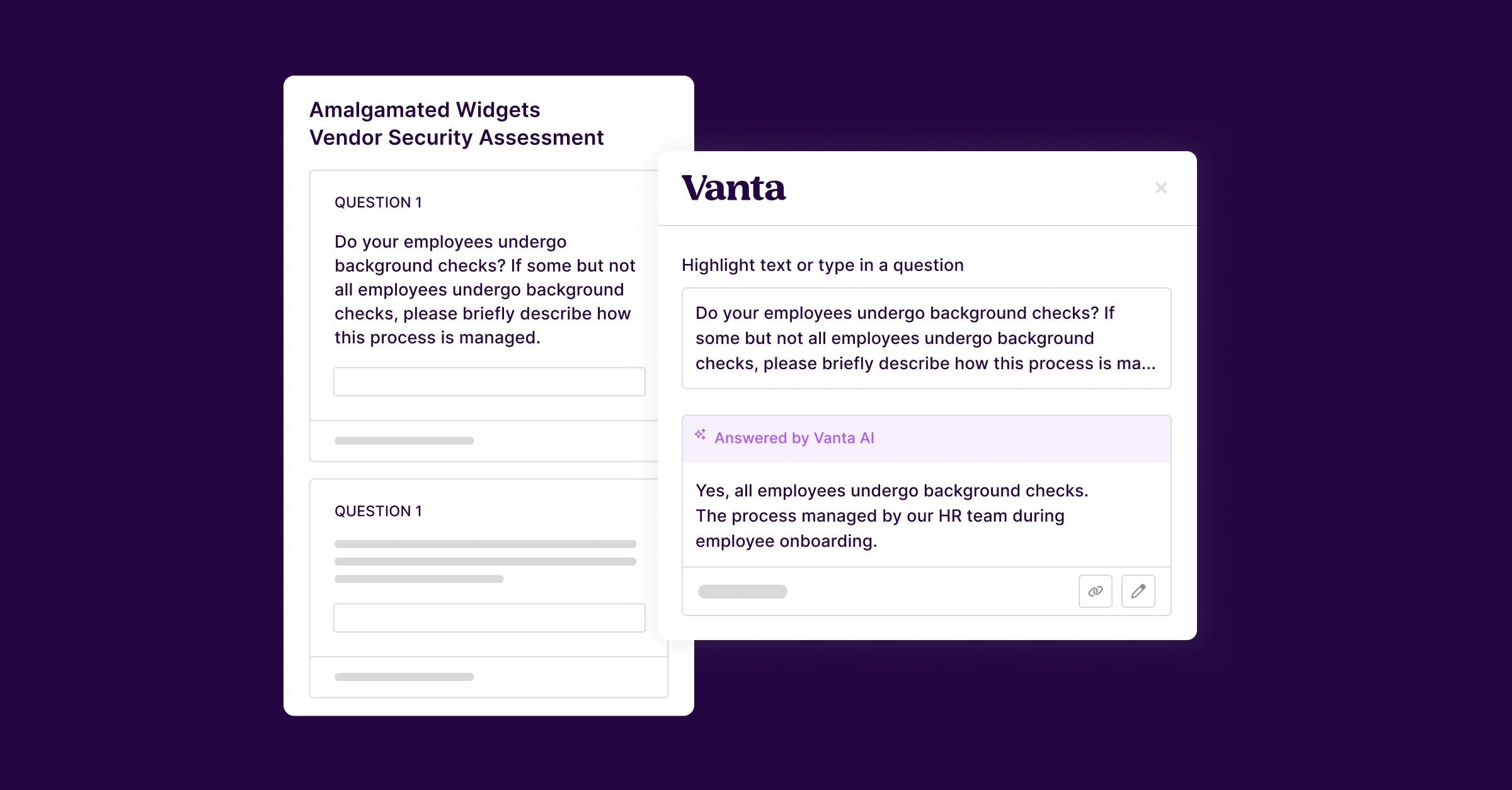
Trust Center chat
Our Trust Center chatbot helps customers respond to security questionnaires using AI-generated answers grounded in their own trust data. To make sure those answers stay accurate, relevant, and on-brand, the team built out a robust evaluation system across the maturity model dimensions:
- Three quality dimensions were defined and instrumented as online evaluators triggered via webhooks on every response:
- Relevance (does the answer address the user's query?)
- Faithfulness (is it grounded in retrieved data from our RAG pipeline?)
- Styling (is it concise, well-formatted, and on-tone?)
- An evaluator alignment exercise on the styling evaluator refined the prompt and improved evaluator-to-SME agreement from ~65–70% to ~85–90%, meaning our automated quality checks now closely match what our subject matter experts would say.
- Continuous improvement automations based on feedback surface low-scoring responses for SME review, and improve evaluator alignment datasets based on feedback patterns. This creates a self-reinforcing loop where the system keeps getting smarter over time.
- Human feedback from thumbs up/down ratings in the UI is wired directly into our evaluation traces, capturing real user satisfaction signals continuously.
The result: The Trust Center chatbot moved from yellow to green across three of the five maturity model dimensions—Annotations & Human Feedback, Observability, and Evaluators—and is now positioned for the next leap forward as we evolve toward an agentic Trust Center experience.
The real question to ask yourself
The real question isn't, "Can an LLM answer this?" It's "Can an LLM do this reliably, accurately, and safely, no matter the prompt or context?"
With a DIY integration, you get a model that can respond to a prompt. With Vanta, you get AI that's been shaped by deep prompt engineering, context design, and domain expertise, so you get good answers without having to engineer them yourself. You get a quality system that keeps getting better with every iteration. You get continuous monitoring and observability across your compliance posture. And you get a system of record that keeps you (and your auditors) confident over time.
We're not competing with LLMs. We're built on top of them. The value we add is the quality layer, the domain expertise, and the ongoing system that turns a powerful but unpredictable technology into something you can actually trust with your compliance program.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.










.svg)
.svg)


