







Share this article

Where thinking in engineering happens now
No items found.
Accelerating security solutions for small businesses Tagore offers strategic services to small businesses. | A partnership that can scale Tagore prioritized finding a managed compliance partner with an established product, dedicated support team, and rapid release rate. | Standing out from competitors Tagore's partnership with Vanta enhances its strategic focus and deepens client value, creating differentiation in a competitive market. |
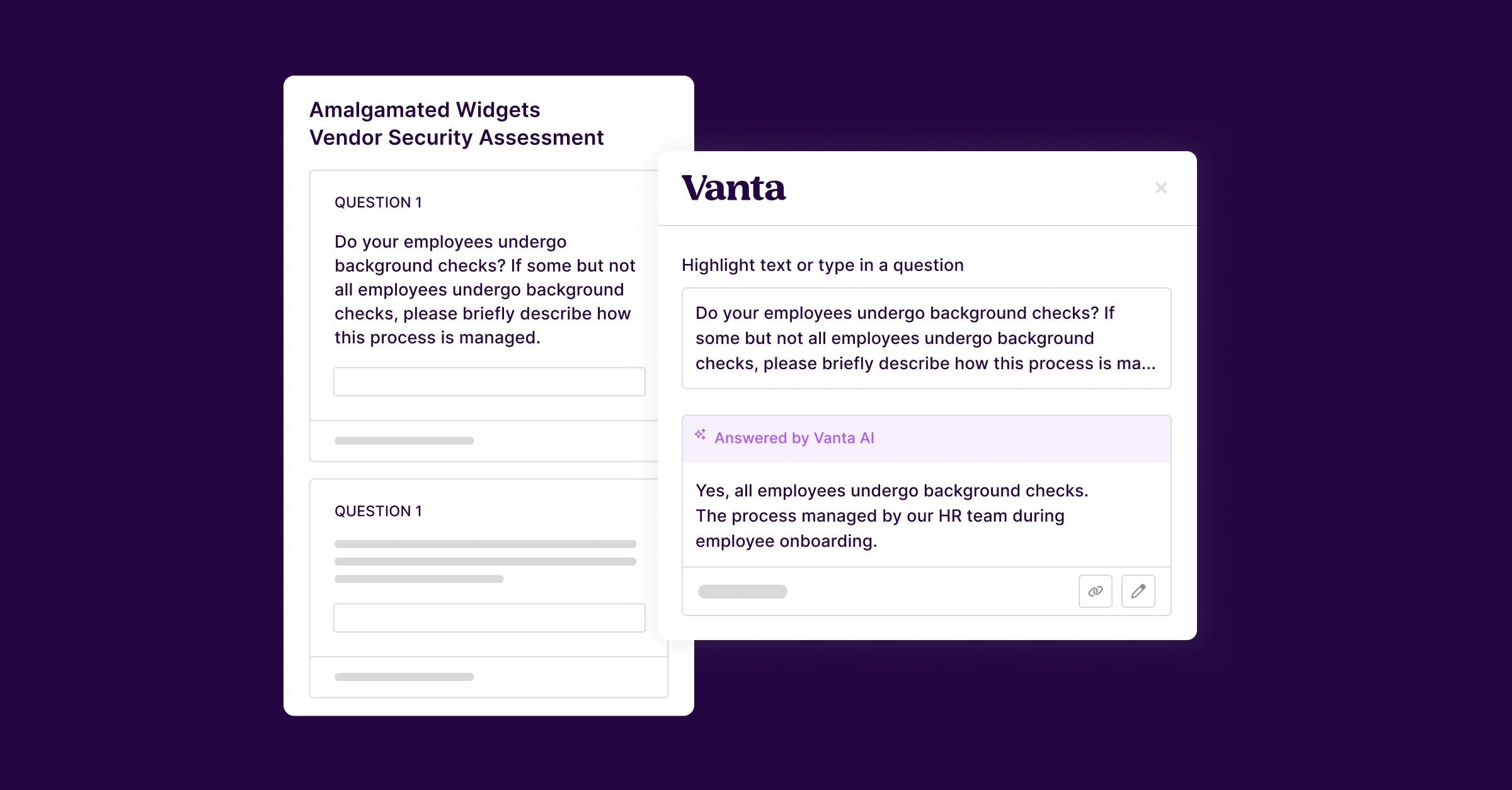
This blog is part of our Trustcraft series, in which we dig into Vanta’s approach to building with AI. Read the first blog in this series to learn more about how we define Trustcraft.
I sent two long docs and a recorded walkthrough for review. The walkthrough did all the work. The docs barely got opened.
That was the moment I started questioning a habit I'd had for years.
I’m a Senior Software Engineer at Vanta, and throughout my career, I defaulted to a doc-first workflow. A doc isn't just an alignment artifact, it's the thinking. The act of writing forces you to confront tradeoffs you'd otherwise paper over. The reader's frustration with a long doc is the cost of the author having actually done the work.
I still believe writing is thinking. However, as AI moves into the dev cycle, I just don't believe the page is where it has to happen.
How AI actually changed my dev cycle
AI made building cheap enough to think against running code, and conversation rich enough to think out loud against a partner.
Both moves do the same thing underneath: They make rigorous thinking less dependent on me being careful.
Pre-AI, surfacing the implicit dependencies of a design or testing whether my framing was right depended on me being careful enough to catch them on the page. Now they get caught in the trying: by an agent pushing back during step one, or by a prototype bumping into them during step two.
The doc is still where I capture what I learned. It's not where the learning has to happen anymore. In other words, AI has shifted what kinds of thinking depend on attention.
Here's what my dev cycle looks like now.
Step one: Make sense of the goal
The thinking part of this used to be a doc-writing exercise: You'd write your way to clarity. Now I do most of it in conversation with an agent: think out loud, sketch a decomposition, surface the assumptions I'm making, push back on my own framing.
There's still a written artifact at the end—a short plan, maybe a page—but it's a capture of thinking that already happened, not the place where the thinking happens.
Step two: Build a working slice
Not a slideware POC but an actual end-to-end thing that runs. AI lets me wire it up in a day or two. The POC's job is to make the abstract concrete. You can argue about a design decision for an hour in the abstract or build the smallest version of it and see what you actually need.
Step three: A recorded walkthrough
The walkthrough does what a framing doc used to do—walk a reviewer through why each piece is the way it is. Except they're watching real behavior, not reading speculative design, and I'm explaining the decisions in line.
The walkthrough is a short-lived artifact, though: It serves the moment of review, then the doc that comes next is what carries the reasoning forward.
Step four: A short doc that captures decisions already made
By the time I'm writing the doc, the prototyping has done the deciding. The doc isn't where I figure things out, it's where I capture what I figured out for reviewers and for whoever has to make a related call later. It lays out the decisions and the reasoning behind them: the alternatives considered, the implicit dependencies, what assumptions I'm betting on, what's deferred on purpose.
What this looks like in practice
The use case
A recent example. I had to figure out where to host a new service we were spinning up. Pre-AI, this would have been days of design-doc writing.
The approach
What I did this time was different. I talked the decision space through with an agent first, decomposing it into the axes that mattered: operational model, cost shape, lock-in, build pipeline, etc.
Then, I built a working prototype of one of the hosting options. Two days, end-to-end, using our existing scaffolding for the security-sensitive pieces. I also built two POCs for the other two options, which cost about a day and a half on top of the first POC: Once the first POC was load-bearing, each additional option was mostly a swap of the deploy model.
The findings
I found things I would not have found from a doc:
- Some hosting platforms ran the monorepo root build target even when I configured them not to—behavior their docs didn't describe
- Some spawned preview builds on every PR in the monorepo, even for changes in unrelated directories
- Some had no clean way to put the app behind a VPN or private subnet—the security controls I needed for the data we'd be processing
None of these surfaced from reading their documentation; all of them surfaced from actually trying.
The hosting decision also turned out to have a second decision tangled into it: whether the code stayed in our existing monorepo or moved into its own repo. Some hosting choices were only viable if I broke the code out; some refactors only paid off if I committed to a specific deploy model. The two decisions were coupled, and the coupling wasn't visible until I'd built far enough to bump into it.
A skeptical reader will say a careful enough analysis on paper could have surfaced the coupling. They're right. The prototype's value isn't that it caught what a doc couldn't—it's that it caught what I didn't, without depending on me being careful enough on a given day. After enough times of being burned by "I should have caught that," I'll take the automatic.
The decision
By the time I'd worked through the prototypes—about four days from start to decision—I'd landed at a different answer than I would have reached from the doc alone. Not because the doc would have been wrong on its own terms, but because it would have been answering the wrong question. It would have ranked hosting options without ever surfacing the code-layout decision they were entangled with.
The doc came after. By the time I started writing it, I already knew the decision. The prototypes had done the deciding. The doc was much shorter than my pre-AI version would have been, mostly because it wasn't where I was figuring things out anymore, it was where I was capturing what I'd already figured out. It described things I'd actually tried, not things I'd reasoned about.
A demo of the result can show you the choice I made. It can't show the choices that turned out to be unbundleable, the implicit deps I would have missed, or why the answer I started with wasn't the one I ended at. That's the part the doc is uniquely good at—and it landed in the doc because AI made the prototyping cheap enough to surface what the doc would later capture. The two artifacts are doing different jobs in the same loop.
The division of labor between docs and POCs
Generalizing: Docs and POCs were both doing five jobs. AI moved two of those jobs to the build:
- Showing what the thing is: No prose beats watching it run
- Generating questions: Reviewers ask sharper, more specific questions when they're staring at running code than when they're reading a future-tense paragraph
The other three are what the doc is uniquely best for:
- The paths you didn't take: The alternatives you considered and rejected, and the dependencies between options
- The conditions under which your choice holds: What assumptions you're betting on, and what would invalidate the design if it turned out to be wrong
- What you're deferring on purpose: Where you're going next, what's explicitly out of scope, and which decisions you've left open
These three are about reasoning rather than state, and reasoning is what an artifact can't carry.
Where this breaks down
This isn't a recipe for every kind of work.
POC-led communication assumes the reviewer can react to a working artifact in their own context, which breaks down when you're crossing team boundaries, touching customer trust, talking to a regulator, or working with a customer commitment that has to land verbatim.
This workflow also leans on judgment, especially in step one. Knowing when an agent's fluent suggestion is right versus when it's right-shaped-but-wrong takes experience that newer engineers won't have, and it might even be harder to develop in a workflow where the agent does the load-bearing exploration. There's a related risk in step two: Working slices can become accidental architecture. "It works, just ship it" is real, and I've fallen into it before. Both of these scale with seniority, as they're easier to navigate the longer you've been making these calls.
The agent-mirroring failure mode is real too, and I've hit it. While I was working through how to put the backend behind a private subnet, the agent kept pushing a compromise: separate hosting for the backend only, since the static SPA frontend is fine being public anyway. Technically viable, but not the right answer for what we needed—too much new infrastructure to maintain, more deployment surface, more state to keep in sync. The suggestion was fluent enough that I almost ran with it; what stopped me was that it didn't smell right. I had to pull myself out of the agent's framing, think the problem through on my own, and then open a fresh session with specific directions to try instead.
What to watch for as AI gets more fluent
AI getting good at the heavy lifting of prototyping and the proposing frees up attention for what else matters. The trap is what AI fluency does to that attention.
When the agent produces a suggestion that runs, my instinct is to check whether it's correct—necessary, but not the load-bearing check. The harder question is whether I'm solving the right problem at all.
Solo writing used to produce friction at the moments when I wasn't sure what I meant, and that friction was where reframing happened. An agent often produces fluency instead. The failure mode of step one isn't bad answers; it's right answers to wrong questions, delivered fast enough that I almost don't notice.
I'm still tuning the ratio. My current default—a short plan, a working slice, a narrated walkthrough, and a doc that captures the decisions—feels right for the kind of work where the surface area is mine and the reviewers are nearby.
I don't yet know what it should look like for a cross-team RFC. I don't yet know how to do it well asynchronously across time zones, where a recorded walkthrough isn't a substitute for a synchronous review and the doc has to do more work again.
If you've found a different split that works on your team, I'd love to hear it. Or, if this is how you think about building, we'd like to talk. See open roles at Vanta.

“
“

FEATURED VANTA RESOURCE
The ultimate guide to scaling your compliance program
Learn how to scale, manage, and optimize alongside your business goals.









.svg)
.svg)


